Introduction à l'analyse exploratoire des données
avec SPSS
B. Entrer les données à partir du questionnaire
Il y a plusieurs manières d'entrer les données :
- directement dans SPSS
- dans Excel ; puis nous importons les données dans SPSS
- dans un éditeur de texte, puis nous importons les données dans SPSS (pas recommandé, sujet à erreur!)
- scannage des données : pour cela il est nécessaire d'avoir un hardware avec logiciel et mise en page spécialisés
La base de données que nous allons utiliser pour toutes illustrations sera : data.sav.
1. Encoder le questionnaire
Il est recommandé de résumer les informations les plus importantes sur les variables rassemblées dans un « tableau de codage ». Ce tableau de codage à deux utilités à deux moments bien précis :
- Pendant l'entrée des données : comme règle de codage des valeurs des variables
- Après l'entrée des données : comme description compacte du fichier des données
Le tableau de codage de notre base de données data.sav contient les informations suivantes :
- Nom de la variable : les items qui appartiennent au même questionnaire devraient porter le même radical dans leur nom (p.ex., exp1, exp2, exp3... pour un questionnaire mesurant l'expressivité des émotions)
- Etiquette de la variable (variable label)
- Etiquettes des valeurs (value labels) : N'oubliez pas une variable d'identification qui établit une relation entre les documents d'un cas (p.ex. questionnaire, prélèvements physiologiques) et les données dans le fichier.
- Numéro d'identification (ID variable): doit être noté sur les questionnaires, pour que l'on puisse facilement retrouver le document d'un sujet afin de contrôler ou corriger des valeurs dans la base de données
 Dans le cas d'une recherche expérimentale, il faut en plus coder la condition dans laquelle on a mesuré les variables dépendantes: variable pour les conditions expérimentales (p. ex. 1 = groupe expérimental, 2 = groupe de contrôle)
Dans le cas d'une recherche expérimentale, il faut en plus coder la condition dans laquelle on a mesuré les variables dépendantes: variable pour les conditions expérimentales (p. ex. 1 = groupe expérimental, 2 = groupe de contrôle)
Exemple du tableau de codage de notre data.sav
| Variable |
Variable label |
Value label |
| id |
Numéro d'identification |
|
| exp1-exp12 |
Expressivité* |
- = jamais ou presque jamais
- = parfois
- = souvent
- = presque toujours ou toujours
|
| bf1 - bf20 |
Big Five (adjectives)* |
- = pas du tout
- = tout à fait
|
| age |
Age |
|
| natio |
Nationalité |
- suisse
- allemande
- français
- italien
- autre
|
* Pour une vue générale sur les variables qui sont mesurées dans une étude, il suffit de donner le nom du questionnaire dans le tableau de codage (p.e.x, « Big Five » pour les 20 items). Dans le fichier SPSS, on peut entrer le contenu de chaque item dans « Variable label » (p.ex., bf1: « amical », bf2: « chaleureux »).
2. Créer un nouveau fichier de données dans SPSS
- Lorsqu'on démarre SPSS, une fenêtre « What would you like to do ? » apparaît par défaut (partie A). On sélectionne « Type in data » et on obtient un éditeur de données vide.
- Si on se trouve déjà dans l'éditeur des données (p. ex., un autre fichier de données est ouvert), il faut cliquer sur File | New | Data
- Une fois l'éditeur de données ouvert, il faut définir les variables dans la vue des variables (Variable View). Pour cela on va s'aider du tableau de codage qu'on a déjà créé à partir de notre questionnaire.
- On commence avec le nom de la première variable. Pour passer à la cellule suivante, appuyez sur TAB ou
 .
.
- Vous pouvez attribuer une ou toutes les caractéristiques d'une variable à une ou plusieurs autres variables !
- Une caractéristique : Copiez la cellule (en cliquant droit : Copy, ou en cliquant sur le menu Edit | Copy) et collez à une ou plusieurs autres cellules (en cliquant droit : Paste, ou en cliquant sur le menu Edit | Paste)
- Toutes les caractéristiques d'une variable : Copiez et collez toute la variable (en cliquant sur le numéro de la ligne, ce qui la grise)
- La seule chose qui ne peut pas être copiée, c'est le nom d'une variable, parce que chaque variable doit avoir un nom unique, comme mentionné précédemment. C'est pour ça que SPSS nomme une variable nouvelles var00001 (que l'on renomme après)
- Pour créer plusieurs nouvelles variables avec le même radical dans leur nom (par exemple bf1, bf2, ..., bf20), il faut
- Entrez la variable bf1 avec son type, son étiquette, etc. (vue : Data View)
- Copiez cette variable.
- Sélectionnez la ligne du dessous de la variable et cliquez sur le bouton de droite de la souris.
- Sélectionnez « Copy variables ».
- Dans la boîte de dialogue qui apparaît entrez le nombre de nouvelles variables à créer ici 19 (20 variables big five moins une déjà entrée), leur radical (nom des nouvelles variables : bf) et le numéro de la première variable qui suivra le radical (2, car on a déjà créer bf1).
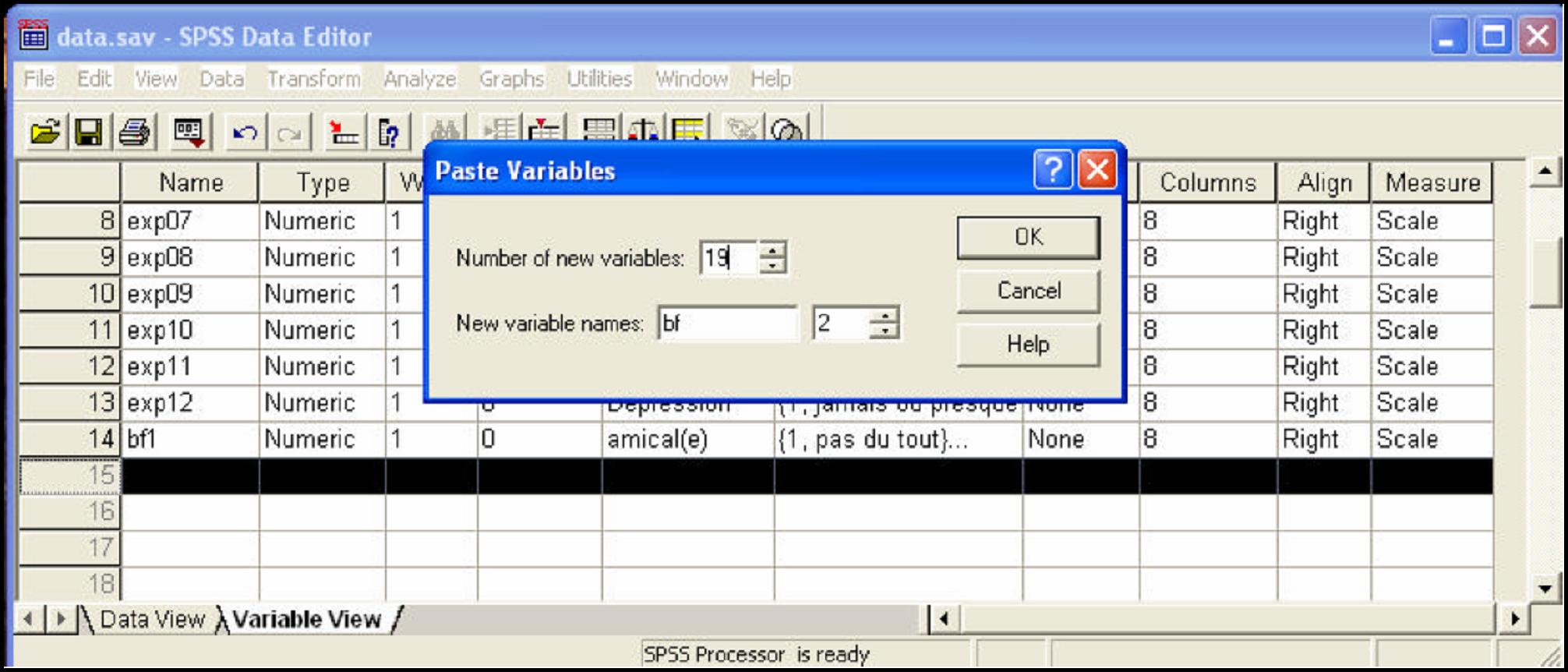
Figure 11
3. Comment coder les réponses ?
Comment coder les variables alphanumériques/série de caractères ?
Exemple : Code d'un sujet (MAPRGE) dans des études longitudinales
Solution : entrez les caractères et définissez la variable comme chaîne de caractère (String)
Comment coder les réponses à réponses courtes ?
Exemple :
Quelle est votre nationalité ? _______________
Solution : Codez les réponses ouvertes avec des valeurs numérique (1 = suisse, 2 = française, etc.) en faisant une liste
Comment coder les réponses multiples ?
Exemple :
Quelles occupations/loisirs avez-vous régulièrement? (plusieurs réponses sont possibles)
 Activités culturelles (expositions, concerts, lecture, université 3e âge, etc.)
Activités culturelles (expositions, concerts, lecture, université 3e âge, etc.)
Activités physiques (natation, marche, club de sport, etc.)
Bricolage (tricot, jardinage, etc.)
Animal domestique
Instrument de musique
Internet, e-mail
Autre : _____________________________________________________
Solution :
- Créez une variable pour chaque catégorie (p.ex, loisir1 - loisir6), codé par 0 = n'a pas ce loisir, 1 = a ce loisir
- Pour les réponses ouvertes (« autre : »), créez soit une variable alphanumérique
(Chaîne de caractère), p.ex. add_lois, soit une variable numérique en faisant une liste des loisirs qui apparaissent
Comment coder les réponses ouvertes ?
Exemple :
Qu'est ce que ces loisirs vous apportent ?
_____________________________________________________________________________________________________________________________
_____________________________________________________________________________________________________________________________
Solution :
- regrouper l'information en catégorie grâce à l'analyse de contenu. Technique que nous n'allons pas traiter ici.
- Donc, nous laisserons de côté ce type de question.
4. Comment coder les valeurs manquantes ?
- Dès qu'on a entré une donnée, toutes les cellules des autres variables numériques de ce cas sont désignés par un point (= « Sysmis », system defined missing) qui est remplacé quand on entre une valeur. Garder le point dans la cellule signifie que la valeur pour cette cellule est manquante et ce type de donnée manquante n'a pas à être définie comme telle car elle est reconnue automatiquement par SPSS comme valeur manquante.
- Garder la cellule vierge pour les variables alphanumériques n'est pas considéré par SPSS comme valeur manquante. Il faut la définir comme telle dans la vue des variables. Pour cela, entrez un espace dans « discret missing values ».
- Entrer un chiffre en dehors de l'étendue de valeurs valables (p. ex. 9 ou 99). Il faut définir ces valeurs dans la vue des variables. Pour cela, entrez un espace dans « discret missing values ».
Conseil et remarques :
- Il est recommandé d'utiliser le pavé numérique à droite du clavier.
- Quand on utilise la touche « Entrée » pour confirmer une donnée, la cellule au-dessous devient active (= prochain cas)!
5. Réduire les erreurs en entrant les données
- Entrez toujours les données « brutes » telles qu'elles sont. Par exemple, il ne faut pas recoder à la main un item (recodage ou transformation (cf partie C)).
- Si vous avez un format de réponse bipolaire avec des valeurs positives et négatives, il est préférable d'utiliser un codage avec uniquement des valeurs positives. Mais il est important d'avoir définit cela dans le tableau de codage du questionnaire.
6. Eliminer et insérer des observations/variables dans la vue de données
- Eliminer un cas : sélectionnez la ligne et appuyez sur « Delete » sur le clavier
- Eliminer une variable : sélectionnez la colonne et appuyez sur « Delete » sur le clavier
- Insérer un cas entre deux autres cas : sélectionnez la ligne au-dessus de laquelle vous voulez insérer une observation et cliquez sur Data | Insert cases ou cliquez droit : Insert cases.
- Insérer une variable entre deux autres variables : sélectionnez la colonne avant celle où vous voulez insérer une variable et cliquez sur Data | Insert variables ou cliquez droit : Insert Variables.
7. Fusionner des fichiers de données
Ajouter des observations
On a deux fichiers contenant des variables similaires, mais des observations différentes (par exemple, saisie d'une moitié des questionnaires par Paul et saisie de l'autre moitié par Pierre avec pour but d'avoir un et un seul fichier à la fin). Pour cela il faut ouvrir le premier fichier, c'est-à-dire celui qui sera pour nous notre fichier de travail. A partir du menu, faites Data | Merge files | Add cases : cherchez votre deuxième fichier.
La boîte de dialogue qui apparaît vérifie si les deux fichiers contiennent les mêmes variables (avec les mêmes noms). Par défaut, toutes les variables de même nom seront incluses Si ce n'est pas le cas, les variables non appariées se trouvent dans la section « Unpaired Variables ».
 Attention : Il est important que le nom des variables, ainsi que le type, l'étiquette et les valeurs et les données manquantes soient définis exactement de la même manière dans les deux fichiers, sinon SPSS définira une variable avec même nom comme « Unpaired variables » (fenêtre de gauche) - toujours vérifier que les variables communes aux deux fichiers qui nous intéressent se trouvent bien dans « Variables in new working data file ».
Attention : Il est important que le nom des variables, ainsi que le type, l'étiquette et les valeurs et les données manquantes soient définis exactement de la même manière dans les deux fichiers, sinon SPSS définira une variable avec même nom comme « Unpaired variables » (fenêtre de gauche) - toujours vérifier que les variables communes aux deux fichiers qui nous intéressent se trouvent bien dans « Variables in new working data file ».
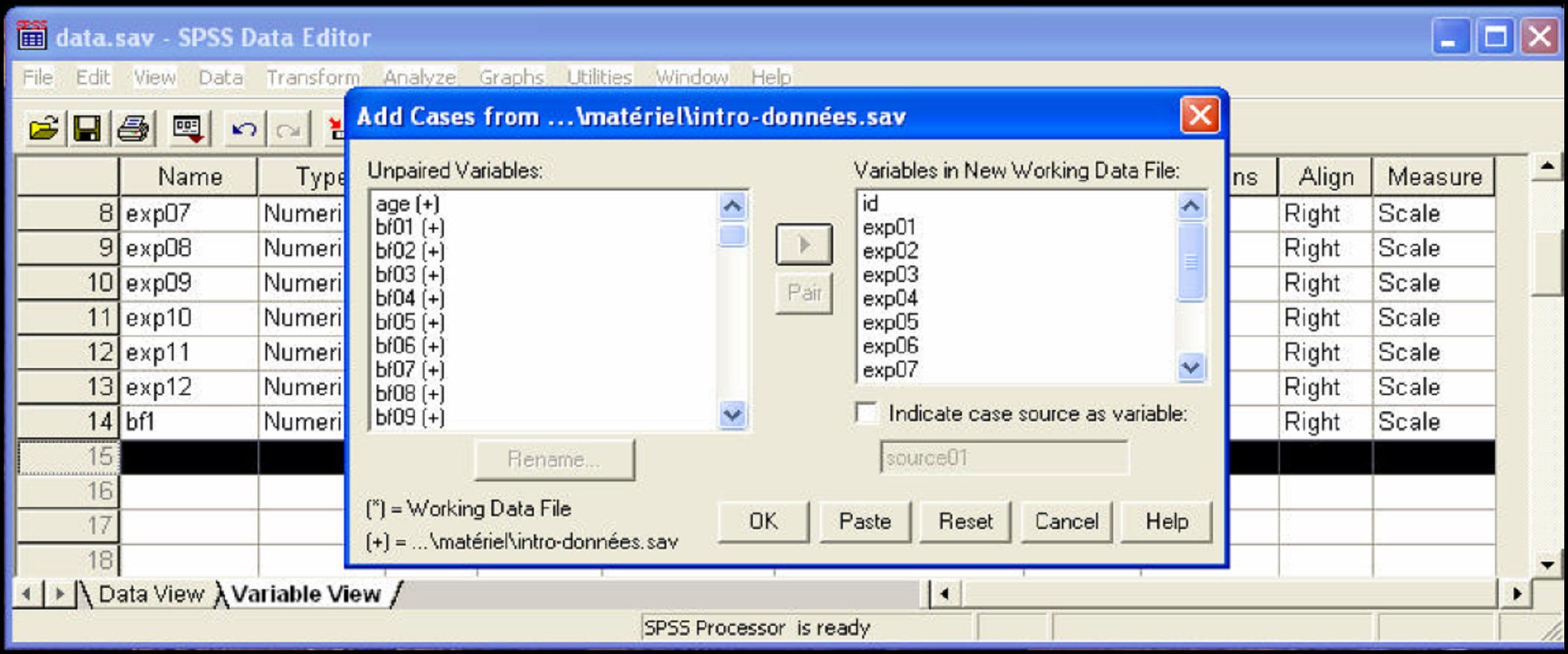
Figure 12
Les variables qui apparaissent seulement dans un fichier de données peuvent quand même être ajoutées en appuyant sur  (les cas de l'autre fichier qui n'ont pas de valeurs à ces variables reçoivent des valeurs manquantes = Sysmis)
(les cas de l'autre fichier qui n'ont pas de valeurs à ces variables reçoivent des valeurs manquantes = Sysmis)
S'il y a des variables dans les deux fichiers qui mesurent la même chose mais qui ne portent pas le même nom (p.ex. par erreur), on peut les apparier. Pour faire cela, il faut sélectionner les deux variables (on sélectionne la deuxième variable en pressant sur la touche CTRL), puis appuyer sur « Paired », on obtient ainsi dans « Variables in new working data file », une nouvelle variable qui se nomme var1 et var2 (dans le fichier fusionné, la variable portera le nom du premier fichier (le fichier de travail)).
Une fois toutes les variables qui nous intéressent sélectionnées, il faut cliquer sur Ok, ce qui ajoute les observations du deuxième fichier au premier. On a maintenant un nouveau fichier de données. Si nous sauvons ce fichier en faisant File | Save, cela va écraser le premier fichier. Ce qu'il faut faire c'est File | Save as et on obtient ainsi une nouvelle base de données, différentes des deux initialement utilisées pour sa création.
Ajouter des variables
Si on a deux fichiers contenant les mêmes sujets, mais avec des variables différentes (par exemple, deux expériences différentes avec le même groupe de sujets avec pour but d'avoir des informations supplémentaires sur nos sujets venant de l'autre expérience). Pour cela il faut ouvrir le premier fichier, c'est-à-dire celui qui sera pour nous notre fichier de travail. A partir du menu, faites Data | Merge files | Add variables : cherchez votre deuxième fichier.
Pour pouvoir effectuer cette manipulation, il faut impérativement avoir une variable « clé » pour identifier les différentes observations (p. ex. par un code) et pouvoir fusionner les données. Les valeurs de cette variable clé doivent être identiques (p.ex. une variable alphanumérique doit être entrée de la même façon - par rapport aux majuscules/minuscules et nombre de caractères - attention aux espaces après les derniers caractères !)
- Triez les observations selon la variable clé dans tous les fichiers qu'on veut fusionner : Data | Sort cases.
- Ouvrez le premier fichier et faites Data | Merge files | Add variables: choisissez le deuxième fichier
- Dans la boîte de dialogue qui apparaît, cochez « Match cases on key variables in sorted files » - « Les deux fichiers fournissent des observations ». Il faut sélectionner la variable clé (key variable) d'appariement dans la section de gauche et appuyer sur .
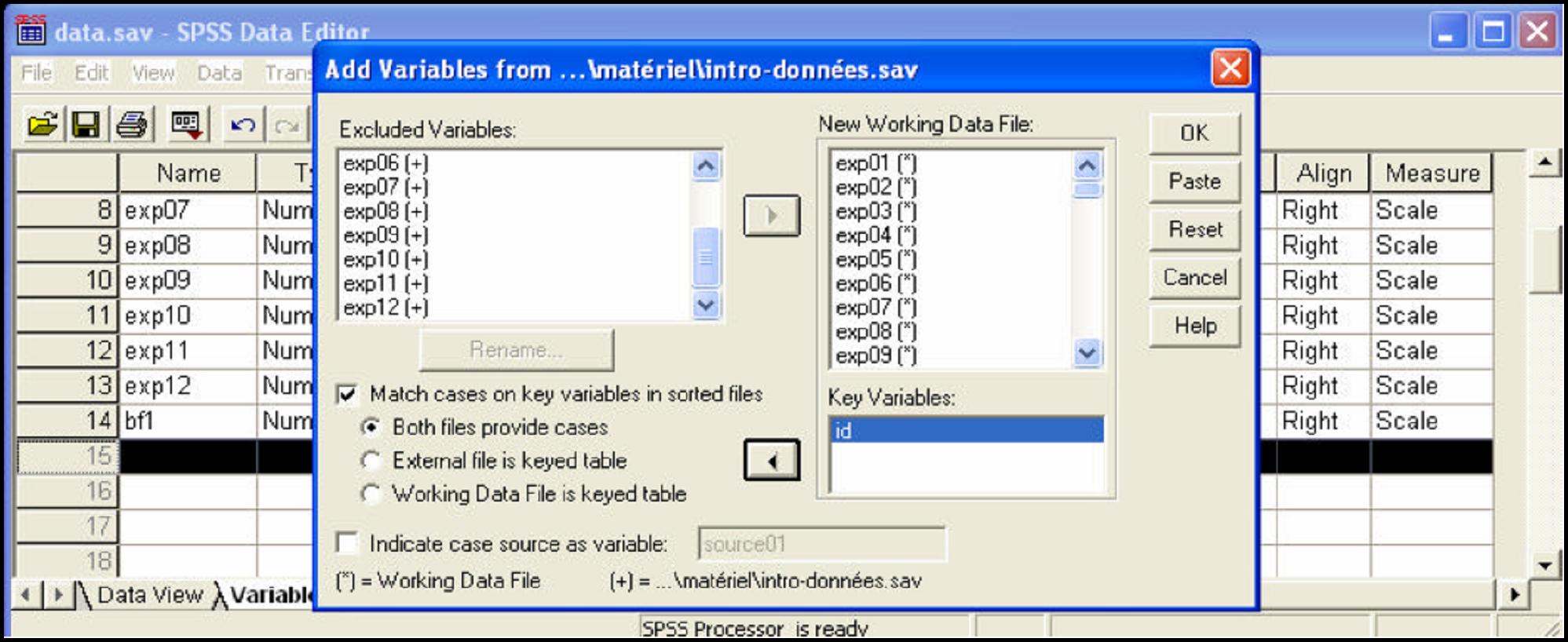
Figure 13
Une fois toutes les variables qui nous intéressent sélectionnées, il faut cliquer sur Ok, ce qui ajoute les variables du deuxième fichier sélectionnées au premier. On a maintenant un nouveau fichier de données. Si nous sauvons ce fichier en faisant File | Save, cela va écraser le premier fichier. Il est beaucoup plus prudent de sélectionner File | Save as ... On obtient ainsi une nouvelle base de données, différentes des deux initialement utilisées pour sa création.
8. Utiliser Excel pour entrer les données dans SPSS
Créer une grille de données avec Excel
- Tapez les noms des variables (pas les étiquettes) dans la première ligne
- Les lignes au-dessous des noms représentent les observations (une observation (cas ou individu) par ligne).
- Sauvegardez les données (File | Save as ...) comme classeur Excel (extension .xls)
Importer les données dans SPSS
- Ouvrir SPSS
- Cliquez sur File | Open a database | New query
- Sélectionnez « Fichiers Excel », cliquez sur suivant
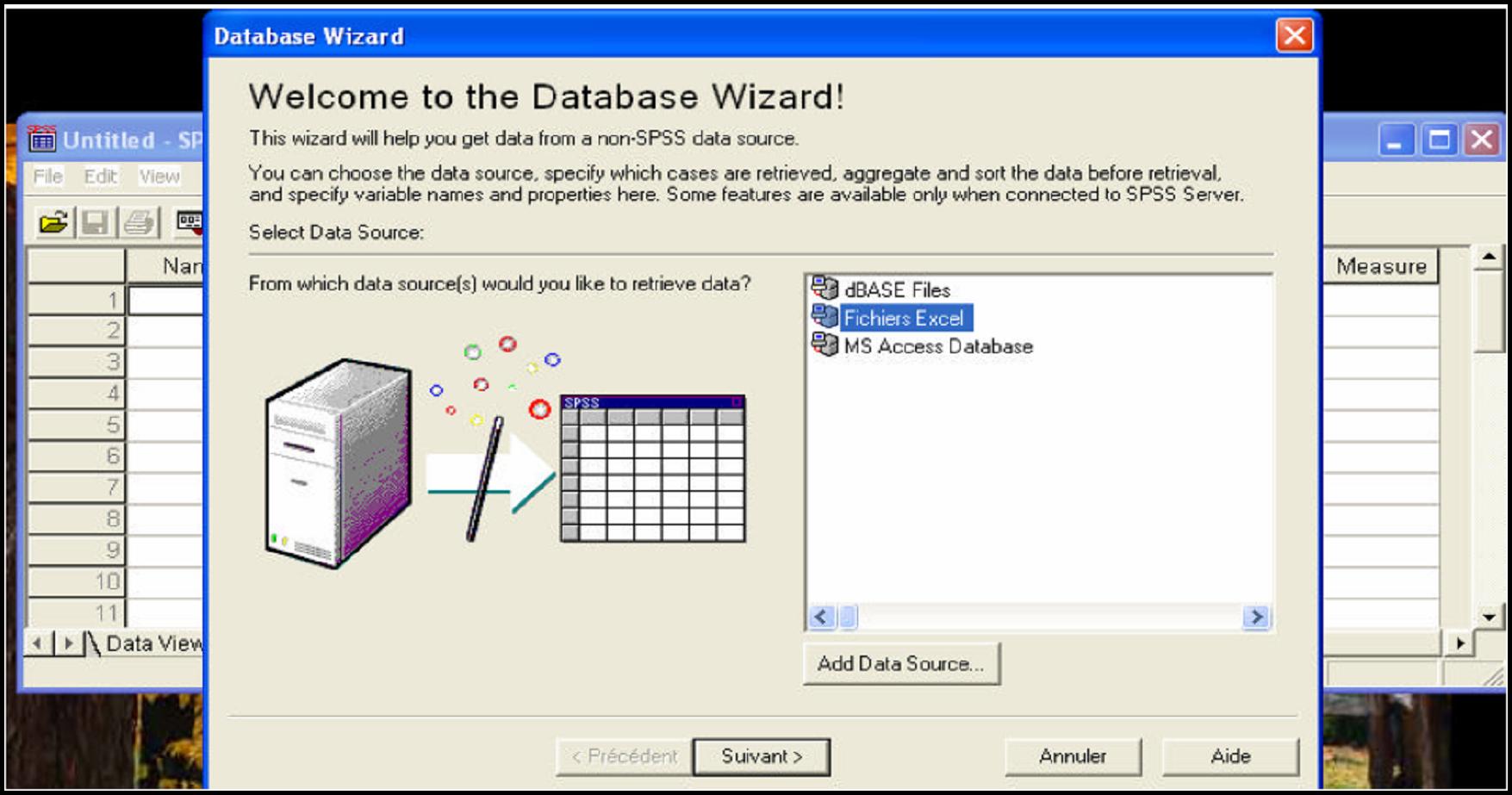
Figure 14
- Sélectionnez la ou les feuilles Excel où se trouvent les données dont vous avez besoin en faisant glisser les feuilles ou les variables dans les feuilles qui nous intéressent dans la fenêtre de gauche vers la fenêtre de droite. Puis cliquez sur suivant.
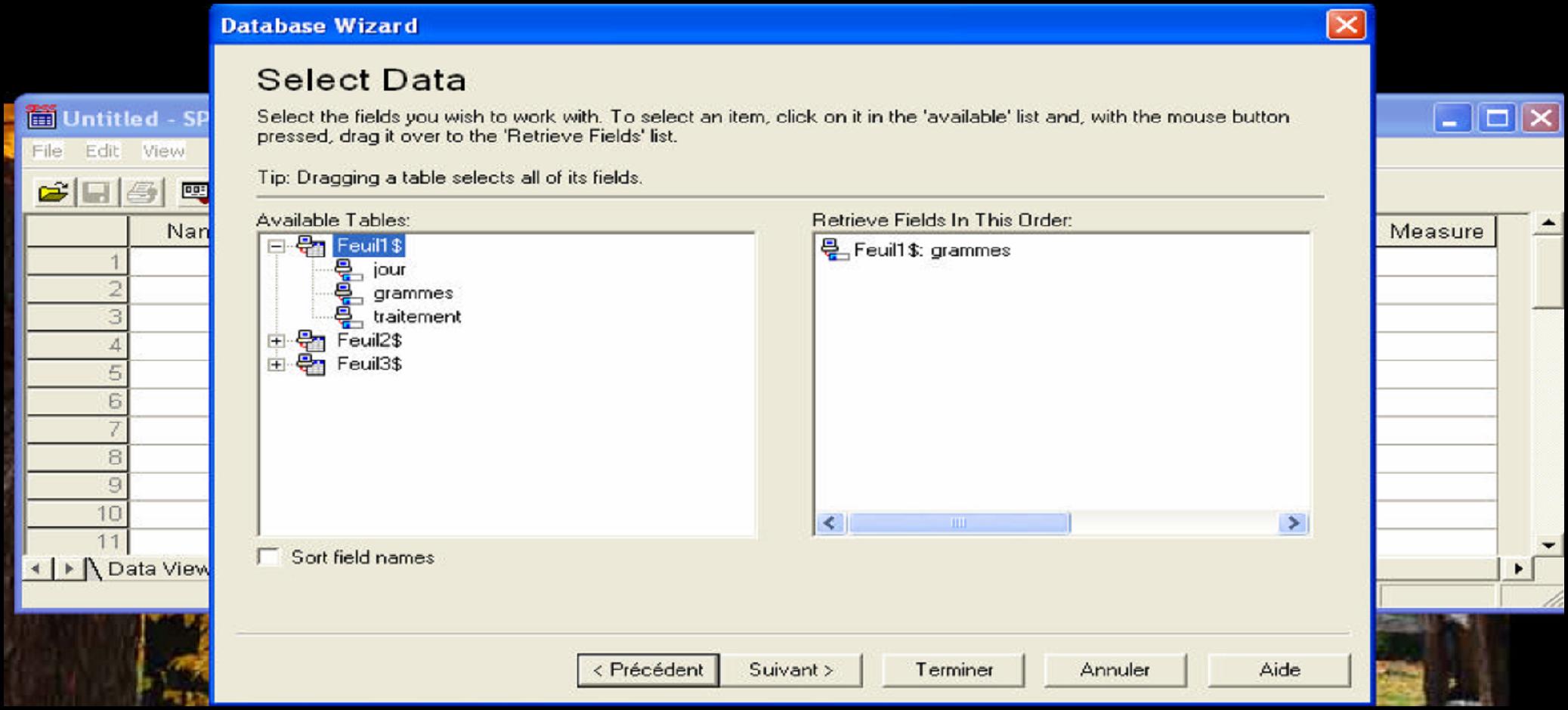
Figure 15
- Définir les variables : type des variables, étiquettes, valeurs, etc.
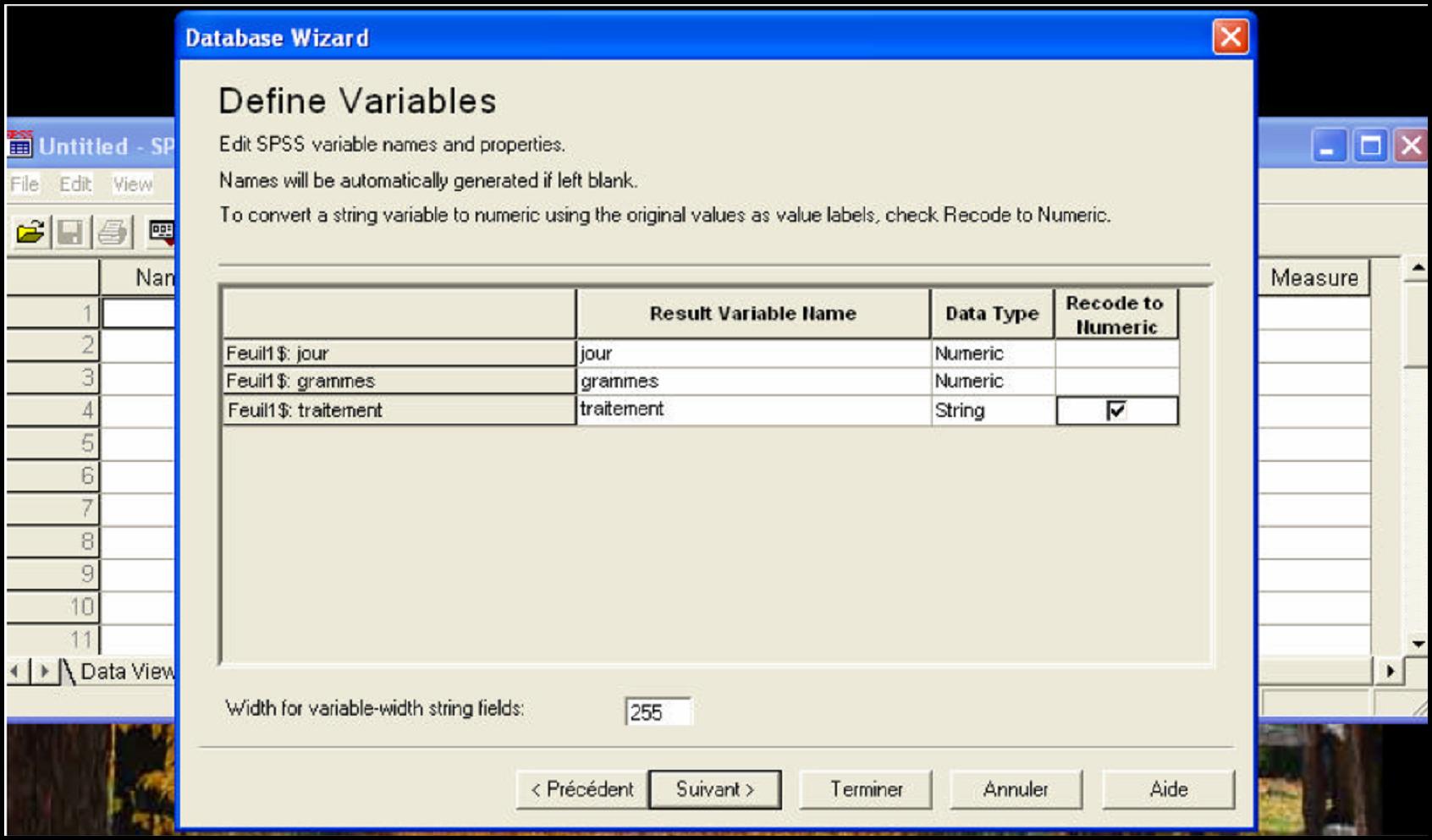
Figure 16
- Terminer et Sauvegardez les données (File | Save as...) comme fichier SPSS (extension .sav).
9. Utiliser un fichier texte pour entrer les données dans SPSS
Créer une grille de données avec un fichier texte
- Ouvrir un fichier texte (p.ex. notepad)
- Tapez les noms des variables dans la première ligne que vous séparer soit par un point-virgule (ou autre séparateur comme tab)
- Les lignes au-dessous des noms représentent les observations (une observation (cas ou individu) par ligne) et chaque valeur de la ligne doit être séparé par un séparateur (toujours utiliser le même séparateur).
- Sauvegardez les données (File | Save as...) comme classeur texte (extension .txt)
Importer les données dans SPSS
- Ouvrir SPSS
- Cliquez sur File | Read text data...
- Spécifiez l'arrangement de vos variables : types de séparateur, est-ce que chaque ligne correspond à un cas, est-ce que le fichier contient le nom des variables sur la première ligne, etc.
- Terminer et Sauvegardez les données (File | Save as...) comme fichier SPSS (extension .sav).
10. Eliminer les erreurs de l'entrée de données
Deux types d'erreurs possibles : a) la valeur fausse est une valeur dans l'étendue des valeurs valables ou b) la valeur fausse est une valeur en dehors de l'étendue des valeurs valables.
On peut repérer les erreurs du type (a) qu'en comparant les données vraies avec les données entrées. Mais cela est très coûteux, d'où l'importance d'être très minutieux en entrant les données ! Donc seules les erreurs de type (b) peuvent être repérées et éliminées après l'entrée des données.
Pour cela, il faut inspecter les valeurs minimales et maximales de toutes les variables en passant par Analyze | Descriptive Statistics | Frequencies. Il faut sélectionner toutes les variables numériques (en utilisant la souris ou les touches SHIFT et 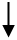 ) et ajoutez-les dans la section droite , puis cliquez dans « Statistics », choisissez « Minimum » et « Maximum ».
) et ajoutez-les dans la section droite , puis cliquez dans « Statistics », choisissez « Minimum » et « Maximum ».
Figure 17
Dans la page des résultats, le tableau « frequencies » peut être pivoté en double-cliquant sur le tableau et cliquant sur le menu Pivot | Transpose rows and columns ce qui rend le tableau plus facile à lire.
S'il y a des valeurs dehors de l'étendue valable :
- Vérifier combien de valeurs sont fausses : pour chaque variable ayant un minimum trop petit ou un maximum trop grand. Pour cela, il faut inspecter les tableaux de fréquences pour les variables ayant des valeurs erronées et noter le nombre de ces valeurs et leurs valeurs numériques.
- Corriger les valeurs fausses dans la vue des données : pour cela il faut trouver la variable p. ex. à l'aide du menu Utilities | Variables... « Go to » et la sélectionner. Puis allez dans Edit | Find et entrez la valeur fausse que vous cherchez et cliquez sur « Find next ». Activez la cellule. Ensuite, cliquez sur le menu Utilities | Variables, choisissez la variable d'identification et cliquez sur « Go to » : la cellule montre le numéro du cas cherché.
- Vérifiez la valeur correcte dans les documents (p. ex. questionnaire) de ce cas et corrigez-la dans la base de données
Attention : Après avoir trouvé la cellule avec une valeur fausse, il semble peut-être plus facile de noter le numéro de la ligne dans la grille de données (au lieu
d'aller via le menu). Mais le numéro de la ligne ne doit pas être identique avec le numéro d'identification du cas !!! (p. ex. si le fichier a été trié par une autre variable ou si la variable d'identification a des valeurs manquantes)
Excercice 2 :
Si vous voulez tester votre connaissance, cliquez ici !
Début de page
This document was created by Elaine Tio | Last modified: 08/01/2007 | Valid HTML | CSS | Page Travaux


